Oftentimes, we struggle with picking a donor pool for SCMs due to spillovers or the event being so massive that it is hard to argue for clean donors in principle. This blog post shows you one way we can get around that problem via using the synthetic historical control method. It is a flavor of synthetic controls, as the name suggests.
Notations
The notation for this method (as it is presented in the paper) makes my head hurt, so I will simply quote directly from my paper that currently uses this method in hopes that I can spell it out clearly.
Let \(\mathbb{R}\) denote the set of real numbers, and let \(\|\cdot\|_1\) denote the usual \(\ell_1\) vector norm. Throughout, I denote sets using calligraphic letters (e.g., \(\mathcal{T}, \mathcal{S}, \mathcal{N}\)) for clarity. Scalars are represented using plain lowercase letters (e.g., \(h, t, n, m\)), and matrices are denoted by bold uppercase letters (e.g., \(\mathbf{X}, \mathbf{W}, \mathbf{Y}\)). Given a vector \(\mathbf{x} = (x_1, x_2, \dots, x_T)^\top \in \mathbb{R}^T\) and an index set \(\mathcal{I} \subseteq \{1, \dots, T\}\), I write \(\mathbf{x}_{\mathcal{I}} \coloneqq (x_t)_{t \in \mathcal{I}} \in \mathbb{R}^{|\mathcal{I}|}\) to denote the subvector of \(\mathbf{x}\) corresponding to indices in \(\mathcal{I}\), preserving their original order.
Let \(\mathcal{T} = \{1, 2, \dots, T\}\) index time. Define the pre-treatment period as \(\mathcal{T}_1 \coloneqq \{t \in \mathcal{T} : t \leq T_0\}\) and the post-treatment period as \(\mathcal{T}_2 \coloneqq \{t \in \mathcal{T} : t > T_0\}\). The number of post-treatment periods is \(n = T - T_0\). Let \(m \in \mathbb{N}\) denote the evaluation window length, i.e., the number of periods used to construct the SHC match. Define the evaluation period as the final \(m\) months of the pre-treatment period:
Let \(\mathbf{y} = (y_1, y_2, \dots, y_T)^\top \in \mathbb{R}^T\) denote the observed outcome vector for the treated unit. Define the pre-treatment outcome vector \(\mathbf{y}_{\text{pre}} \coloneqq \mathbf{y}_{\mathcal{T}_1} \in \mathbb{R}^{T_0}\), the evaluation subvector \(\mathbf{y}_{\text{eval}} \coloneqq \mathbf{y}_{\mathcal{T}_{\text{eval}}} \in \mathbb{R}^m\), and the post-treatment outcome vector \(\mathbf{y}_{\text{post}} \coloneqq \mathbf{y}_{\mathcal{T}_2} \in \mathbb{R}^n\). The evaluation subvector \(\mathbf{y}_{\text{eval}}\) is the target pattern to be reconstructed using convex combinations of earlier segments from the pre-treatment period.
To reconstruct the evaluation window, we compare it against earlier segments of the treated unit’s own pre-treatment trajectory. Define the donor matrix \(\widetilde{\mathbf{Y}}_{\text{pre}} \in \mathbb{R}^{m \times N}\) as a collection of \(N\) overlapping length-\(m\) subvectors extracted from the smoothed pre-treatment series. Each column is a contiguous subvector of the form \(\widetilde{\mathbf{y}}_{[i, i+m-1]}\), with \(i\) ranging over eligible start points in \(\mathcal{T}_1\) that precede the evaluation window.
The Synthetic Historical Control (SHC) Estimator
The SHC method is a synthetic control-style estimator that constructs a counterfactual using only the treated unit’s own historical data. This makes SHC particularly useful when no clean donor units are available, for instance, when all states or countries are exposed to a shock like COVID-19. SHC begins by smoothing the pre-treatment outcome time series \(\{y_t\}_{t=1}^{T_0}\) using local linear regression, which helps reduce noise and better recover the underlying trend. In practice, I use leave one out cross validation to choose the bandwidth for the Gaussain kernel. The result of all this is a smoothed series:
where \(N = T_0 - m - n + 1\) is the number of segments, where each column is a historical “donor” segment used to predict post-treatment outcomes. In this case, we have \(n\) post-treatment observations. I will give a toy example. Suppose we have \(T_0 = 14\) days of pre-treatment data, and we want to: use \(m = 2\) days to define the evaluation window (i.e., the last 2 days before treatment) and predict \(n = 1\) day into the post-treatment period. Then, to build a valid donor, each segment must be \(m + n = 3\) days long: the first \(m\) days are used to match the evaluation window, and the last \(n\) days are used to forecast the post-treatment period.
So, how many such segments can we extract from the 14 pre-treatment days? We need to ensure that each 3-day segment fits entirely within the pre-treatment window. The last such segment would be \((\widetilde{y}_{12}, \widetilde{y}_{13}, \widetilde{y}_{14})^\top\). Thus, the total number of eligible segments is: \[
N = T_0 - m - n + 1 = 14 - 2 - 1 + 1 = 12.
\]
Each donor segment looks like: \[
\widetilde{\mathbf{y}}_{[i, i + m + n - 1]} = (\widetilde{y}_i, \widetilde{y}_{i+1}, \widetilde{y}_{i+2})^\top
\quad \text{for } i = 1, \dots, 12.
\]
The first \(m = 2\) elements are used for fitting the evaluation window. The final \(n = 1\) element is used to extrapolate into the post-treatment period. So the donor matrix for evaluation looks like: \[
\widetilde{\mathbf{Y}}_{\text{pre}} =
\begin{bmatrix}
\widetilde{y}_1 & \widetilde{y}_2 & \cdots & \widetilde{y}_{12} \\
\widetilde{y}_2 & \widetilde{y}_3 & \cdots & \widetilde{y}_{13}
\end{bmatrix} \in \mathbb{R}^{2 \times 12},
\] and the corresponding donor matrix for forecasting (aligned with each segment’s next day) is: \[
\widetilde{\mathbf{Y}}_{\text{post}} =
\begin{bmatrix}
\widetilde{y}_3 & \widetilde{y}_4 & \cdots & \widetilde{y}_{14}
\end{bmatrix} \in \mathbb{R}^{1 \times 12}.
\]
We use the pre period for the historical controls to fit our evaluation period for our treated unit. As in normal SCM style, all of those weights are applied to the full segment matrix to give us the in and out of sample predictions. So the SHC counterfactual for day 15 is estimated as: \[
\widehat{y}_{15} = \widetilde{\mathbf{Y}}_{\text{post}} \cdot \mathbf{w}^\ast,
\] where \(\mathbf{w}^\ast\) are weights that optimally match the evaluation window using the \(\widetilde{\mathbf{Y}}_{\text{pre}}\) matrix.
SHC selects weights \(\mathbf{w} \in \mathbb{R}^N\) to minimize the squared distance between the evaluation window and a convex combination of donor segments. We also have a penalty term:
The term on the left is the ususal OLS loss function. Here, \(\mathbf{C}_0\) contains the eigenvectors of the donor pool’s Grammian matrix. We use this term to stabilize the optimization, since in practice we will always have more predictors than the segment length allows. The authors go into more detail on this in their paper on page 11.
Choosing Our Historical Segments
To avoid using too many donor segments and overfit, SHC implements a forward selection algorithm. The authors in the paper sort of choose an arbitrary number of donors to use. They find that 27 donor segments about does the job, in practice. However, I did not like that they wanted to use a stepwise method with no stopping rule, since this just means that the size of the donor pool we use is kind of arbitrary. So, I write my own forward selection method. Starting with an empty set, it adds one donor at a time, each time choosing the segment that most reduces the in-sample MSE.
where \(\text{MSE}_j\) is the in-sample mean squared error using \(j\) donors, and \(\lambda = \log(m)\). The algorithm stops when BIC increases for two steps in a row. Presumably, we could use a better one, so if you have suggestions let me know. I borrowed this idea from the forward selected PDA approach.
Estimation in Python
In order to get these results, you need Python (3.9 or greater) and mlsynth, which you may install from the Github repo. You’ll need the most recent version.
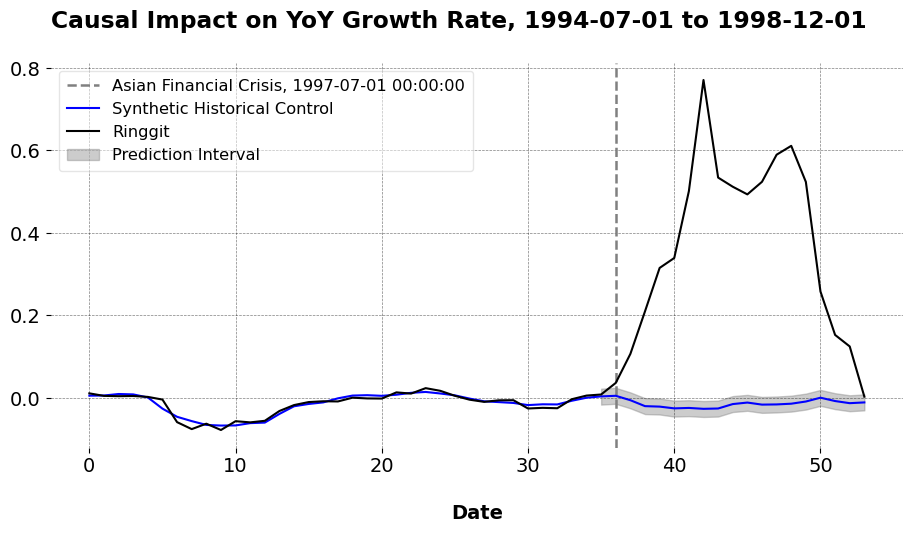
This example uses the Malaysian Ringgit as an example. Its currency was affected by the Asian Financial Crisis. I use the SHC method to estimate the impact the crisis had on the growth rate of the spot exchange rate, taken from FRED’s database. We can see my code below, where I use 36 months (3 years) of a pretreatment period.
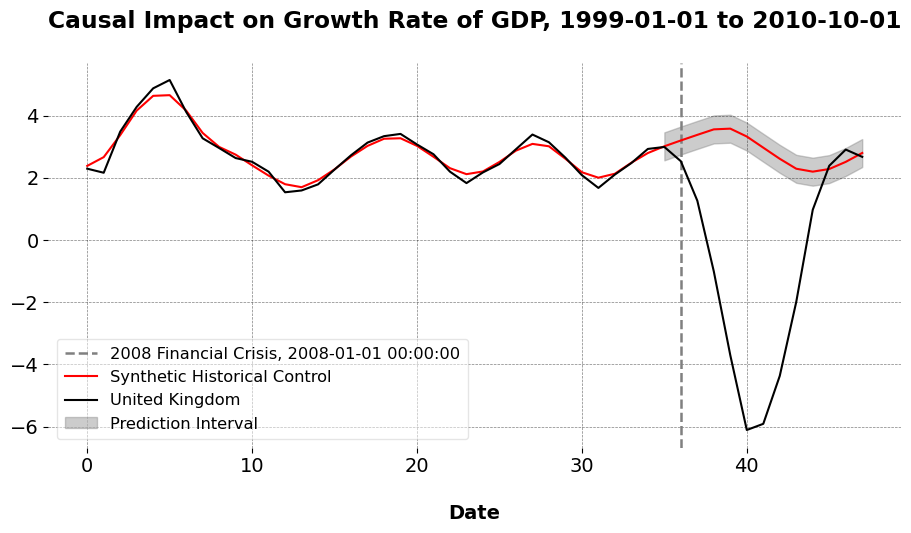
Now I do the effect of the 2008 Financial Crisis, because why not? I look at the effect for the U.K., but of course we may choose any nation we like. I use the precomputed annual growth rate of GDP.
The ATT for the growth rate is -3.755, meaning the growth of the economy slowed down by 3 percentage points over the next three years following the 2008 Financial Crisis/Crash.
Of course, these examples are both financial crises, but you can literally do this with anything that we have a big enough time series to do it with. No reason this method cannot work with promotions for sales of goods, ad campaigns, tourism (my current application!) or other questions we may care about.
Caveats
The authors note that this approach will not work with trendy data (which makes sense due to the convex combination of donor periods). In other words, you need to detrend it first if a trend exists. This is why I use the growth rate to (ideally) avoid this issue.
In principle, I like this method. I wonder what would happen if we just did this same method of donor pool construction, but just slapped on the Robust SCM method for the weight solution, where we take the low rank structure of the pre-treatment period and learn the weights via OLS. Unclear as to whether/why we could not do this, or add in other penalty type terms or intercepts to adjust for this, either. If the idea is just that “we think the future will look like some combination of the untreated past”, then who’s to say that using the low-dimensional subspace of pre-treatment periods wouldn’t be a good idea? The authors do not propose inference methods either, so I use the agnostic conformal prediction intervals from the scpi package. Presumably though there’s a better way than this.
Anyways, all of that is really for another paper. The SHC method itself is not even published just yet, so unclear how popular it will become or if others will want to extend it for other things. But now of course, you too may use it, should you wish.