Calculus is the heart of SCM, which is unsurprising given that it’s an optimization problem. However, after years of reading about SCM, I’ve never ever seen somebody solve a simple synthetic control by hand. I do this below. So, with the help of a little Boyd-ie, I went through the process of finding the weights by hand.
Solved By Calculus
We aim to find a synthetic control as a convex combination of the donors that matches the target vector as closely as possible:
\[
\begin{aligned}
\mathbf{w}^{\ast} &= \underset{\mathbf w \in \mathbb{R}_{\ge 0}^2}{\operatorname*{argmin}} \;\; \|\mathbf y - \mathbf Y \mathbf w\|_2^2 \\
\text{s.t.} \quad & \mathbf 1^\top \mathbf w = 1,
\end{aligned}
\]
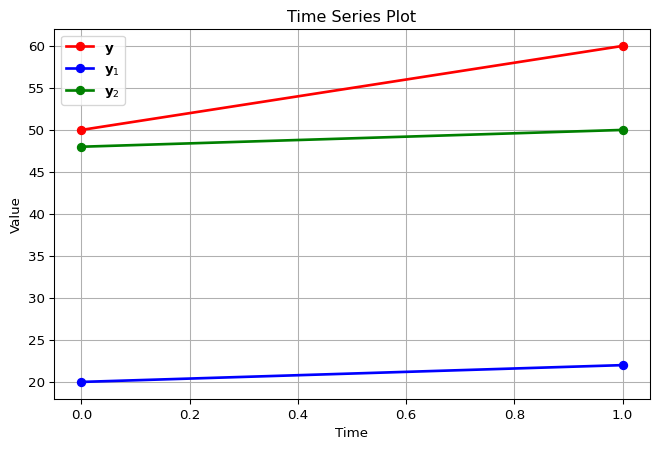
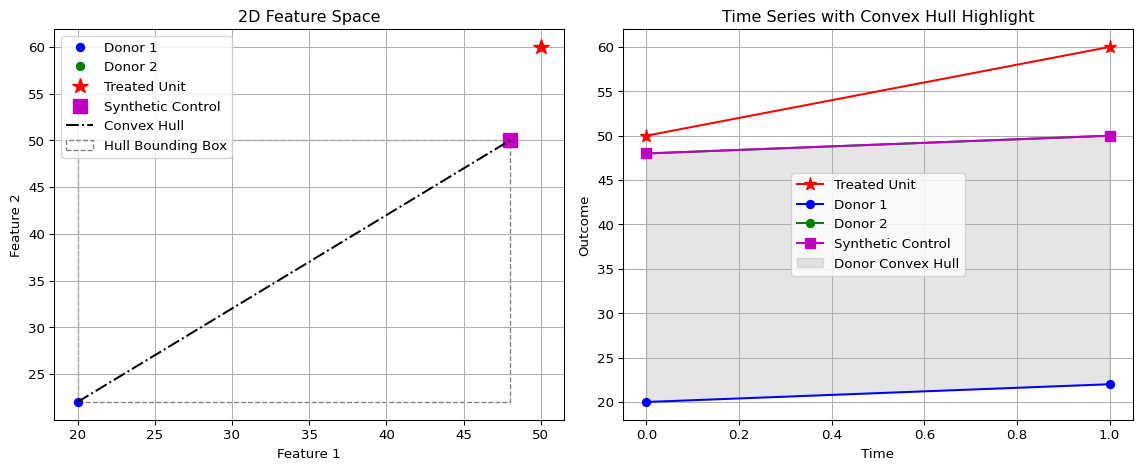
where \(\mathbf{Y} = \begin{bmatrix} \mathbf{y}_1 & \mathbf{y}_2 \end{bmatrix} = \begin{bmatrix} 20 & 48 \\ 22 & 50 \end{bmatrix}\).
The synthetic control is a weighted average:
\[
\hat{\mathbf{y}} = w_1 \mathbf{y}_1 + w_2 \mathbf{y}_2,
\quad w_1, w_2 \geq 0, \quad w_1 + w_2 = 1.
\]
of control units. Specifically, it is a convex combination. A convex combination of a set of vectors \(\mathbf{w}_1, \mathbf{w}_2, \dots, \mathbf{w}_n \in \mathbb{R}^N\) is any vector of the form
\[
\mathbf{w} = \sum_{i=1}^n \alpha_i \mathbf{w}_i \quad \text{subject to} \quad \alpha_i \ge 0 \text{ for all } i = 1, \dots, n, \quad \sum_{i=1}^n \alpha_i = 1.
\]
Notice how in this case two donor units. From the definition above, it helps us to define one weight in terms of the other; for example, if the optimal value for one weight is 0.2, the other one must be 0.8.
Substituting \(w_2 = 1 - w_1\):
\[
\hat{\mathbf{y}}(w_1) = w_1 \mathbf{y}_1 + (1 - w_1)\mathbf{y}_2
= \mathbf{y}_2 + w_1(\mathbf{y}_1 - \mathbf{y}_2),
\]
and since \(\mathbf{y}_1 - \mathbf{y}_2 = \begin{bmatrix}-28 \\ -28\end{bmatrix}\), we have
\[
\hat{\mathbf{y}}(w_1) = \begin{bmatrix} 48 \\ 50 \end{bmatrix} + w_1 \begin{bmatrix}-28 \\ -28\end{bmatrix}
= \begin{bmatrix} 48 - 28 w_1 \\ 50 - 28 w_1 \end{bmatrix}.
\]
This is just the predicted outcome if we put weight \(w_1\) on donor 1 and weight \(1-w_1\) on donor 2 (again, defining weight 1 in terms of weight 2). By definition, the residuals are the differences between the treated outcomes and the synthetic prediction:
\[
\mathbf{r}(w_1) = \mathbf{y} - \hat{\mathbf{y}}(w_1).
\]
Plugging in:
\[
\mathbf{r}(w_1) =
\begin{bmatrix} 50 \\ 60 \end{bmatrix} -
\begin{bmatrix} 48 - 28 w_1 \\ 50 - 28 w_1 \end{bmatrix}.
\]
So:
\[
\mathbf{r}(w_1) = \begin{bmatrix} 2 + 28w_1 \\ 10 + 28w_1 \end{bmatrix}.
\]
Let’s define the main calculus rules we’ll use:
Constant Multiple Rule. If \(f(x) = c \cdot g(x)\), where \(c\) is a constant and \(g(x)\) is differentiable, then the derivative of \(f\) with respect to \(x\) is:
\[
f'(x) = c \cdot g'(x).
\]
This rule allows you to pull constants out of derivatives.
Sum Rule. If \(f(x) = g(x) + h(x)\), where \(g(x)\) and \(h(x)\) are differentiable functions, then the derivative of \(f\) with respect to \(x\) is the sum of the derivatives of the individual functions:
\[
f'(x) = g'(x) + h'(x).
\]
This rule allows us to differentiate each term of a sum separately and then add the results.
Chain Rule. If a function is composed as \(f(x) = g(h(x))\), where \(h(x)\) is the inner function and \(g(u)\) is the outer function (with \(u = h(x)\)), then the derivative of \(f(x)\) with respect to \(x\) is:
\[
f'(x) = g'(h(x)) \cdot h'(x).
\]
Differentiate the outer function with respect to the inner function, then multiply by the derivative of the inner function with respect to \(x\).
To find the minimizing weight, we differentiate \(f(w_1)\) with respect to \(w_1\).
Since \(f(w_1)\) is a sum of two terms, the linearity of the derivative (sum rule) allows us to differentiate each term separately and then sum the results:
\[
f(w_1) = (2 + 28 w_1)^2 + (10 + 28 w_1)^2
\]
To find the minimizing weight, we differentiate \(f(w_1)\) with respect to \(w_1\). Since \(f(w_1)\) is a sum of two terms, we can differentiate each term separately and then sum the results, according to the linearity of the derivative.
Let’s begin with the first term: \((2 + 28 w_1)^2\). We recognize this as a composition of two functions, so we apply the chain rule. Let
\[
h_1(w_1) = 2 + 28 w_1 \quad \text{(inner function)}, \quad g_1(u) = u^2 \quad \text{(outer function)}.
\]
Now we compute the derivatives:
\[
\frac{\mathrm{d} g_1}{\mathrm{d} u} = 2 u, \quad \frac{\mathrm{d} h_1}{\mathrm{d} w_1} = 28.
\]
The first result comes from the power rule applied to the outer function, and the second comes from differentiating the linear inner function. Applying the chain rule, we obtain
\[
\frac{\mathrm{d}}{\mathrm{d} w_1} (2 + 28 w_1)^2 = \frac{\mathrm{d} g_1}{\mathrm{d} u} \bigg|_{u = h_1(w_1)} \cdot \frac{\mathrm{d} h_1}{\mathrm{d} w_1} = 2 (2 + 28 w_1) \cdot 28.
\]
Next, consider the second term: \((10 + 28 w_1)^2\). Similarly, let
\[
h_2(w_1) = 10 + 28 w_1, \quad g_2(v) = v^2.
\]
The derivatives are
\[
\frac{\mathrm{d} g_2}{\mathrm{d} v} = 2 v, \quad \frac{\mathrm{d} h_2}{\mathrm{d} w_1} = 28.
\]
Again, these results come from the power rule for the quadratic outside function and the linear term inside the parentheses. By the chain rule, the derivative of the second term is
\[
\frac{\mathrm{d}}{\mathrm{d} w_1} (10 + 28 w_1)^2 = 2 (10 + 28 w_1) \cdot 28.
\]
Combining the two terms by the sum rule, the derivative of the full objective function is
\[
\frac{\mathrm{d} f}{\mathrm{d} w_1} = 2 (2 + 28 w_1) \cdot 28 + 2 (10 + 28 w_1) \cdot 28.
\]
Now we have our first order conditions. We start by setting the derivative to zero
\[
2 (2 + 28 w_1) \cdot 28 + 2 (10 + 28 w_1) \cdot 28 = 0.
\]
We can factor out \(2 \cdot 28\):
\[
2 \cdot 28 \left[ (2 + 28 w_1) + (10 + 28 w_1) \right] = 0.
\]
Simplifying inside the brackets gives
\[
(2 + 28 w_1) + (10 + 28 w_1) = 12 + 56 w_1,
\]
so the equation becomes
\[
2 \cdot 28 \cdot (12 + 56 w_1) = 0.
\]
Since \(2 \cdot 28 \neq 0\), we can safely divide both sides of the equation by this constant factor 56, isolating the parentheses that contains our variable:
\[
12 + 56 w_1 = 0.
\]
We see that we can simplify this with the greatest common factor. Dividing both terms by 4 yields
\[
\frac{12}{4} + \frac{56}{4} w_1 = 0 \quad \implies \quad 3 + 14 w_1 = 0.
\]
Finally, solving for \(w_1\), we obtain
\[
14 w_1 = -3
\]
and finally
\[
w_1 = -\frac{3}{14}.
\]
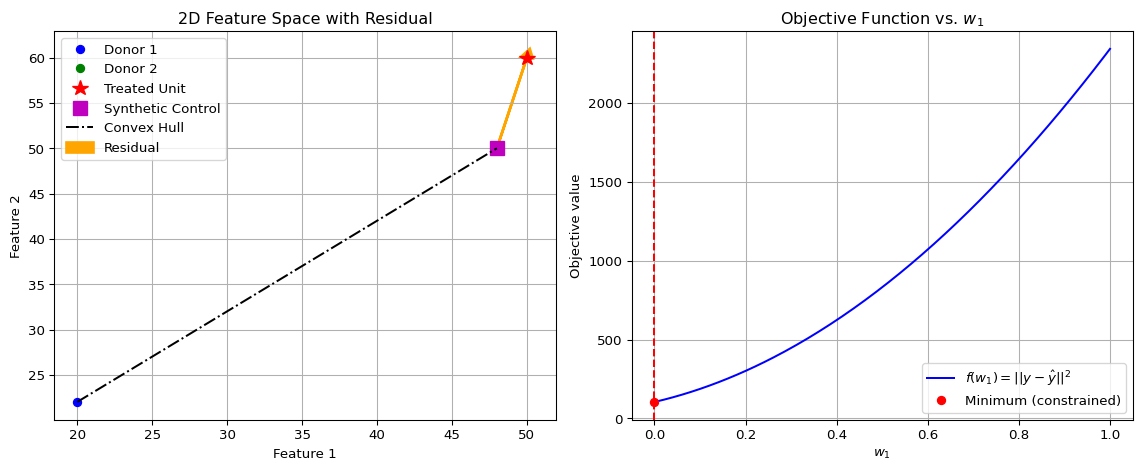
This is the unconstrained minimizer of \(f(w_1)\). However, it lies outside the feasible interval \([0,1]\) for the weights. The constrained minimum is therefore at the nearest boundary of the feasible set, which is \(w_1 = 0\). Correspondingly, \(w_2 = 1\). Evaluating the objective at the boundary points:
\[
f(0) = 2^2 + 10^2 = 104, \quad f(1) = 30^2 + 38^2 = 2344.
\]
The minimum occurs at \(w_1 = 0, w_2 = 1\), giving the synthetic control
\[
\hat{\mathbf{y}} = \mathbf{y}_2 = \begin{bmatrix} 48 \\ 50 \end{bmatrix}.
\]
The reason I chose a corner solution is because I wanted to think about the circumstnaces uner which the model will not work. Solving for the optimal and yet non-ideal answer provides interesting insights as to how we can think about applyinng SCM in practice, as I will show below.